
Since that time, we have far outgrown 8-bit. Games are now built on top of gigabytes of dedicated graphics memory and have a little over 2 million pixels of screen real estate. Shouldn't more horsepower and more pixels lead to more beautiful realism and as a result, a more appealing character? And it's not just the tech that's getting better. Today's artists are more skilled and have way more tools than those early developers. Shouldn't the expertly crafted detail lead to a better product?
In my opinion, character design is getting worse, and it's all because of the Uncanny Valley.
In brief, the Uncanny Valley is a postulate widely accepted in robotics and computer animation that the more a fabricated character tries to act and look like a real human, the more we subconsciously notice what's wrong, and therefore reject the fabrication as creepy.
Here's an example of state of the art work in games from Ninja Theory. The detail they're getting out of the high res scans is mind boggling - down to finger print accurate resolution.
And I have to admit that the still images of the CG character in neutral pose are looking pretty good. Where it all breaks down is when the character starts moving. Even if the game makers capture a wide range of neutral and active poses, humans are so adept at discerning meaning from facial differences as little as millimeters apart, there's no algorithm that can blend between those poses that captures a completely believable human face. Most who aspire to be actors have a hard time achieving believability, why do we think a computer could do any better?
What's frustrating is that even though today's game designers know they are making creepy characters, many of them have this unshakeable belief that with a little more technology and a few more clever ideas, they will eventually converge to the limit. If you rephrase the Uncanny Valley premise from the creative's perspective, the more you try to climb out of the Valley, the harder it gets. Sounds like a classic case of diminishing returns.
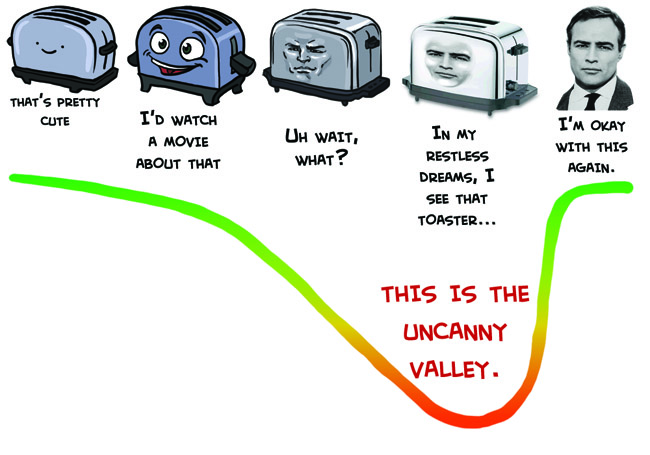 |
| Image grabbed from Manly Guys doing Manly Things. |
I think there are two alternative paths that could lead towards better ways out of the Valley.
The first is obvious: don't even try climbing the difficult side. Use our wide range of tools, talent and technology to make something you would never see in real world - like a stylized illustration come to life. We are much better as humans in finding appeal in the fantastic than we are at forgiving flaws in the realistic. In the 80s, tech limitations forced stylization. Now, stylization is a choice worth making.
The second comes from thinking how film captures appealing character. Humans are not very sensitive to temporal gaps in what we see and so flashing a moving picture 24 times a second is not distracting and has been used for over a century in the cinema. We also know that a film of a good actor can be incredibly appealing. So what if instead of capturing high resolution scans of static poses, we scan actors as they act at around 30 times per second. There's already promising tech going in this direction coming out of teams like 8i.com, Uncorporeal, and Microsoft Research.
We can then play that 3D capture back at 30 poses per second without needing any blending for the in between frames, even if the game is rendering at 60 or 90 fps. Where this becomes a problem is that game developers like a simplified model, usually in the form of a joint hierarchy. With a simplified model, developers can drive a character that can be affected by interactive input, like when the player hits the "jump" button. Furthermore, the joint hierarchy is a good way to compress movement data so you don't need to download 1TB of data to see a cutscene.
But I think these are the problems worth working on. Instead of finding a way to fabricate acting with an algorithm, even if that algorithm is fed by scans and motion capture, find algorithms that solve the problems of using dynamically scanned acting.
Stop struggling to climb out of the Uncanny Valley on the hard side. We should either walk back up the easier side towards more stylized characters, or avoid falling into the Valley all together by finding better ways to record actors in 3D. In the latter case, the problems worth solving are around interactivity and compression, problems better solved with a computer anyways.